Geeky tech types love acronyms. A popular one getting tossed around these days is the expression “Web 3.0.” For those of you who might have been sleeping during your Internet History classes, this third generation of the Web is one which expands upon the linkages, accessibility and collaboration enabled by Web 2.0 technologies such as social media and content-management systems. Web 3.0 extends the idea of a more open internet by seeking to fundamentally change the way the internet is coded and data is represented. The idea is that if its possible to standardize the way content is organized on the web into a family of categories, then those categories themselves will have basic meaning to other sites and applications that might be accessing that data.
I’ve probably lost you by now, so let’s start with a real world example…
Traditionally, most web developers have taken an ad-hoc approach to their craft, without much regard for how well their web applications play with others. In other words, if I’m coding a website, I might name the different content areas of my site whatever the Heck I felt like naming them. For instance, the container element that has all my addressing information could be called “DavesLocation.” Another website designer, however, might name his address area “AddressArea.” This is a simple example but illustrates the absence of consistent standards we’re talking about.
The Semantic Web is all about fixing this sort of coding caprice.
Inconsistent standards pose other problems for the modern Web. There is an increasing wave of content-sharing web services out there which all need to talk to one another. Facebook, Google+, mobile applications, Twitter and others all have a need to exchange information. A lack of standards for content creation make these tasks harder.
One already-popular Web 2.0 technique that illustrates the idea behind the Semantic Web is the practice of tagging article content in blogs. Most of us have probably noticed that, when we’re reading a blog article, there are often category labels that let us — and search engines — know what broad content category that particular post falls into. Building on this principle, the Semantic Web organizes not just the content but the actual structure of a website into “categories.” This helps to create a universal vernacular that all web applications and search engines can understand.
Let’s look at a brief example:
I’ve got a business with an upcoming promotional event that I want to plug in to the website. I can mark it up the usual way, without very helpful semantics (the bold items represent the metadata):
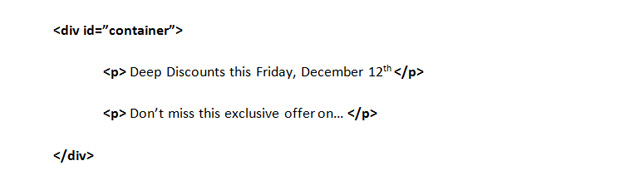
Or I can mark it up in a way that search engines can make sense of and display in real-time search results:
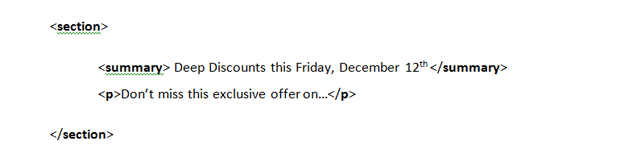
As you can see in the second version, I’ve provided a semantics framework that the search engines are familiar with, making the brief summary of the event that I provided much more likely to show up in search listings, in a more tightly controlled manner.
There are other benefits to the widespread adoption of semantics standards that are less apparent in the short-term, but nevertheless important. Essentially, when your web developer produces code that is marked up with descriptive, meaningful semantics, it allows the next developer that works on the project to dive in with a better understanding of what’s going on. With this extra bit of planning, making changes and updates becomes much more manageable and cost-effective over the lifetime of the project.
The major hurdle facing the broader adoption of standards behind the Semantic Web is the extra planning entailed and the lack of widespread adoption. As attitudes change, though, and as applications and information-sharing sites on the web increasingly demand standards, the Semantic Web will become a reality.
With the web moving towards personalization of the user experience and increased information sharing, this particular aspect of the New Internet teaches us all that, sometimes, it does indeed pay to quibble over semantics.